diff --git a/.main.cpp.swo b/.main.cpp.swo
new file mode 100644
index 0000000..322b485
Binary files /dev/null and b/.main.cpp.swo differ
diff --git a/.main.cpp.swp b/.main.cpp.swp
new file mode 100644
index 0000000..7d6e9be
Binary files /dev/null and b/.main.cpp.swp differ
diff --git a/Makefile b/Makefile
new file mode 100644
index 0000000..7bc54f5
--- /dev/null
+++ b/Makefile
@@ -0,0 +1,36 @@
+# A simple Makefile to make the process of compilation easier for the user :-)
+# With this makefile, instead of writing the cumbersome command for the whole project compilation into a single binary,
+# simply write (on the terminal),~~
+
+# make a : TO complile the project files
+# make run: TO run the compiled binary files
+# make clean: TO delete all the built binary files.
+
+#~~~~~~~~~~~~~~~~~~Libraries~~~~~~~~~~~~~~~~~~~~~~~~~#
+# Install readline library: sudo apt-get install libreadline6 libreadline6-dev
+# Install boost library: sudo apt-get install libboost-all-dev
+
+#~~~~~~~~~~~~~~~~~~VARIABLES~~~~~~~~~~~~~~~~~~~~~~~~~#
+CC = g++ -std=c++11
+# -std=c++11 This flag provides C++11 support in the g++ compiler
+CFLAGS = -c -Wall
+# argument Wall is used for giving warnings
+
+#~~~~~~~~~~~~~~~~~COMMANDS~~~~~~~~~~~~~~~~~~~~~~~~~~~#
+a: all
+run: all
+ ./all
+all: main.o parser.o lexical.o syntax_analyser.o processCtrl.o
+ $(CC) main.o parser.o lexical.o syntax_analyser.o processCtrl.o -o all -lboost_system -lboost_filesystem -lreadline
+main.o: main.cpp
+ $(CC) $(CFLAGS) main.cpp
+parser.o: parser.cpp
+ $(CC) $(CFLAGS) parser.cpp
+lexical.o: lexical.cpp
+ $(CC) $(CFLAGS) lexical.cpp
+syntax_analyser.o: syntax_analyser.cpp
+ $(CC) $(CFLAGS) syntax_analyser.cpp
+processCtrl.o: processCtrl.cpp
+ $(CC) $(CFLAGS) processCtrl.cpp
+clean:
+ rm -rf *o all
\ No newline at end of file
diff --git a/README.md b/README.md
index 1215082..68ecbd5 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,93 @@
-# Shell-Development-Project
+
+# Abstract
+ Most useful interaction with a UNIX system occurs through the shell. Using a series of easy to remember and
+ simple commands, one can navigate the UNIX file system and issue commands to perform a wide variety of tasks.
+ Even though it may appear simple, the shell encapsulates many significant components of the operating system.
+# Introduction
+ This project aims to create a command line interface that provides almost every functionality provided by the
+ BASH and look forward to implementing minute tweaks and quick fixes that can influence its performance in terms
+ of memory utilization, execution time and error handling. Moreover, the implementation methods make use of new
+ styles and libraries.
+ This includes implementation of concepts of Compiler Design (lexical analysis, syntax analysis, error handling)
+ amalgamated with the concepts of process creation and control in Unix Systems.
+ The project aims to make the shell more memory-efficient by making use of C++ Boost:: Filesystem Library that
+ enables Directory Traversal and implementation of Change Directory command (cd) in the Unix Environment. Also,
+ a new method of constructing SLR (1) parsing table has been improvised, this reduces the wastage of memory
+ caused using conventional Sparse Matrix Method.
+ Hence, the newly developed shell has been named BISHOP (Boost Implemented OPerational SHell).
+
+ Implementation Details
+
+# Environment:
+ The shell maintains many variables which allow the user to maintain settings and easily navigate the filesystem.
+ Two of these that are particularly important are the current working directory and the PATH. As its name implies,
+ the current working directory variable keeps track of the user's current directory. The kernel searches in the
+ directories specified by the PATH variable starting with the leftmost directory first.
+ Bishop’s environment uses Boost filesystem Library to check the user’s pwd (Present Working Directory) and
+ execute cd (change Directory) command effectively. Also, the program code makes use of C’s readline library
+ for text completion functionalities originally provided in the BASH.
+
+# Command Analysis:
+ Bishop parses the user input command by performing SLR (1) syntax analysis. The LR (k)-method uses two tables,
+ which describe the behavior of a push-down automaton, used during the parsing process. These two tables,
+ called action table and goto table, are sparse tables. Moreover, the data in them are not homogeneous in
+ structure since both item numbers and right sides of productions are stored.
+ I referred a paper which proposes: a new parsing table structure, which is dense and homogeneous; a parsing
+ algorithm; and an algorithm for generation of this table, based on the SLR (1)-method.
+
+
+
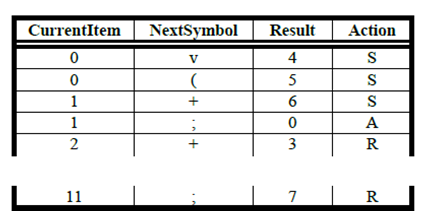
+The proposed parsing table structure has 4 attributes:
+- CurrentItem - the LR (0)-Item on the top the of stack
+- NextSymbol - the next symbol from the input queue
+- Result - an integer whose meaning depends on the value of the attribute Action
+- Action - if action is ‘S’, then Result contains the number of a LR(0)-Item; if action is ‘R’, then Result contains the number of a production; if action is ‘A’, then the input queue is recognized as true.
+
+# Pipelining:
+ UNIX provides a variety of useful programs for use (grep, ls, echo, to name a few).
+ Like instructions in C++, these programs tend to be quite effective at doing one specific thing
+ (Such as grep: searching text, ls: printing directories, and echo: printing text to the console).
+ However, programmers/OS users would like to accomplish large tasks consisting of many individual
+ operations. Doing such requires using results from previous steps in order to complete a larger
+ problem. Bishop supports this through the pipe operation (represented by the character |) just
+ like the BASH using Unix System calls (dup2(int oldfd, int newfd)).
+ A pipe in between two commands causes the standard output of one to be redirected into the standard
+ input of another. An example of this is provided below, using the pipe operation to search for all
+ processes with the name under root user:
+ ps auxx | grep “root”
+# Process Control:
+ Bishop uses the conventional methods of process creation and execution in Unix/Linux (fork () and execvp ()
+ system calls) aided by different implementation techniques like C++ STL (Standard Template Library) classes:
+ std::string and std::vector.
+- fork ():
+Every other process in the system is brought to life through a call to the fork () system call. A process calling fork is copied by the kernel. At this point, the process that called fork is known as the parent, and the newly created process is known as the child since the parent process caused the child to be created. The newly created process is essentially exactly the same as the parent, even having the exact same variables and open _les. Fork is unique in that it is called once by the parent process and returns twice (to the parent and child separately).
+To the parent, fork returns the process id (PID) of the newly created child. To the child, fork returns 0. If the call fails entirely, -1 is returned to the parent, and no child is created.
+
+For more information about fork, see its manpage by calling man 2 fork.
+
+- exec ():
+UNIX provides a function, known as exec, which allows programmer to change a process's address space in order to run an entirely new program. Running an exec command deletes the existing text, data, and stack segments of the existing process and replaces them with those of a new program.
+The system call interface provides a total of six different variations of the exec function which differ only on how they handle input arguments. This means that only one system call (usually execve ()) is actually required to be implemented. The other functions are stubs which perform necessary preparations and then eventually call execve.
+
+Bishop uses execvp (const char *file, char *const argv[]) system call as it maintains a vector of command input strings.
+
+# References:
+- Linux Lectures by Dr. B Frazer
+https://www.youtube.com/watch?v=9seb8hddeK4&index=2&t=7s&list=LLDUlQqsRbRzlDdJlyERjLBw
+- Pipes Lectures
+https://www.youtube.com/watch?v=uHH7nHkgZ4w
+- Machine Problem 4: The UNIX Shell, PDF- Texas A&M University
+- Stevens, W. Richard. Advanced Programming in the UNIX Environment
+- Linux System Programming: Talking Directly to the Kernel and C Library, Author: Robert Love
+- Parsing table structure and algorithm for the LR(k) parsing Method
+ BY: ILTSCHEV, V[elko] I[vanov]
+ [New LR Parsing method.pdf](https://github.com/Akashi96/High-Performance-Linked-Lists/files/1309805/New.LR.Parsing.method.pdf)
+# Necessary Installations:
+- C++ Boost Library:
+ sudo apt-get install libboost-all-dev
+- C Readline Library:
+ sudo apt-get install libreadline6 libreadline6-dev
+
+
+
+
diff --git a/ShellmakingSteps.pdf b/ShellmakingSteps.pdf
new file mode 100644
index 0000000..9f4fc00
Binary files /dev/null and b/ShellmakingSteps.pdf differ
diff --git a/all b/all
new file mode 100755
index 0000000..e999460
Binary files /dev/null and b/all differ
diff --git a/lexical.cpp b/lexical.cpp
new file mode 100644
index 0000000..4350c4e
--- /dev/null
+++ b/lexical.cpp
@@ -0,0 +1,199 @@
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include // -lboost_system: Write this while compiling, this prevents
+ // the linker error.
+#include
+
+#include "lexical.h"
+
+int validateCmd(string cmd)
+{
+ if (cmd == "cd")
+ {
+ return 1;
+ }
+ boost::filesystem::path pathToBin("/bin/" + cmd);
+ boost::filesystem::path pathToBin2("/usr/bin/" + cmd);
+ boost::filesystem::path pathToBin3("/usr/share/applications" + cmd);
+
+ // cout << "path=" << pathToBin << "\n";
+ if (! boost::filesystem::exists(pathToBin) && ! boost::filesystem::exists(pathToBin2) && ! boost::filesystem::exists(pathToBin3))
+ throw std::runtime_error(cmd + ": command not found");
+ return 0;
+}
+
+int validateDir(string dir)
+{
+ // replace(dir.begin(), dir.end(), '~', "/home/akash"); //Cannot use std::replace() because, it replaces char with another char
+ //here we have to replace character with string
+ boost::filesystem::path path(dir);
+ // cout << "current path:" << boost::filesystem::current_path() <
+ // cout << "changed current path:" << boost::filesystem::current_path() <";
+ break;
+
+ case '<': return "";
+ break;
+
+ case '>': return "";
+ break;
+
+ case '&': if (testCmd[1] == ' ')
+ return "";
+ if (testCmd[1] == '&')
+ return "<&&>";
+ else
+ return "";
+ break;
+
+ case '/': return "";
+ break;
+
+ case '"': return "";
+ break;
+
+ default: return "";
+ break;
+ }
+}
+
+int substrPos(string cmd, int it, int &strStartPos, int &strEndPos)
+{
+ if (it == -1) // if iterator is at the beginning of the command string
+ {
+ strStartPos = -1;
+ strEndPos = cmd.find(' ', it + 1);
+ }
+ else
+ {
+ strStartPos = cmd.find(' ', it);
+ strEndPos = cmd.find(' ', strStartPos + 1);
+ // cout << "strStartPos:" << strStartPos << endl;
+ // cout << "strEndPos:" << strEndPos << endl;
+ if (strStartPos == -1) // If no further space is found, means that we have found all
+ { // the tokens
+ return -1;
+ }
+ if (strEndPos == -1 && strStartPos != -1) // If space before the token is found, but not the space after
+ { // the token, this means that we are on the last token.
+ strEndPos = cmd.length(); // In that case, make the variable- that takes the index value
+ // space after a token- take the value of length of the string
+ // i.e. 1 more than the index position of last character.
+
+ if (strEndPos - strStartPos == 1) // if we've reached the end of the string and the last character
+ return -1; // entered by the user is blank: ' '.
+
+ return 0;
+ }
+ }
+ return 0;
+}
+int cmdLexicalAnalysis(string cmd, std::vector & tokenStream, std::vector & tokens, int& pipeCount)
+{
+ int strStartPos, strEndPos, strLength, mark, commandTurn = 1, dirArg = 0;//strStartPos: Stores the index value of space before a token.
+ // srtEndPos: Stores the index value of space after a token.
+ string token, subString;
+ strLength = cmd.length();
+ // cout << "Length:" << strLength << endl;
+ // tokenStream.append("");
+ for (int it = -1; it < strLength - 1; it++)
+ {
+ // cout << "Iter:" << it << endl;
+ mark = substrPos(cmd, it, strStartPos, strEndPos); // Find the position of space characters
+ // before and after a token in the command
+ // cout << "Mark:" << mark << endl;
+ if (mark == -1)
+ break;
+ it = strStartPos; // Move the iterator to the space preceding the next token
+ // cout << "Updated Iter:" << it << endl;
+ subString = cmd.substr(strStartPos + 1, strEndPos - strStartPos - 1);
+ token = lexems(subString); // Stores the string value of token type
+ // cout << "token:" << cmd.substr(strStartPos + 1, strEndPos - strStartPos - 1) << endl;
+
+ if (token == "")
+ {
+ it = cmd.find('"', it + 2) - 1;
+ // cout << it;
+ token = "";
+ }
+ if (dirArg == 1)
+ {
+ token = "";
+ while (cmd[strEndPos - 1] == '\\') // when the file or directory name consists of spaces.
+ {
+ subString.erase(strEndPos - strStartPos - 2); // erase backslash(\) character from path string.
+ // bool::filesystem::exists() does not require the use of
+ // backslash(\) to check the existence of file or directory
+ // it is the feature of the shell.
+ it ++; // move the iterator by one space to help finding the next two spaces in the string using substrPos()
+ substrPos(cmd, it, strStartPos, strEndPos);
+ subString = subString + " " + cmd.substr(strStartPos + 1, strEndPos - strStartPos - 1);
+ // Take the next substring and add it to the
+ // previous substring to treat them as
+ // one space separated directory path.
+ it = strStartPos; // reset the position of the iterator, so that at the very end when, blackslash(\)
+ // is not found, we DO NOT repeat the substring already taken in consideration
+ // and unwillingly add it to the tokenstream as a
+ }
+ validateDir(subString);
+ dirArg = 0;
+ }
+ if (commandTurn == 1)
+ {
+ token = ""; // This converts the token type of string at the beginning of the
+ // command or just after the PIPE operator to
+ commandTurn = 0; // commandTurn helps to ensure whether or not, the next token
+ // needs to be of type or not.
+ /* Now, since we know that the token has to be a unix command, we need to validate it.
+ The subString variable already contains the token value, just send it to validateCmd() to check the
+ validity of the */
+ dirArg = validateCmd(subString);
+ if (dirArg == 1)
+ token = "";
+ }
+ if (token == "" || token == "<&&>")
+ {
+ commandTurn++;
+ if (token == "")
+ pipeCount++;
+ }
+ tokenStream.push_back(token);
+ tokens.push_back(strdup(subString.c_str()));
+ }
+ return 0;
+}
\ No newline at end of file
diff --git a/lexical.h b/lexical.h
new file mode 100644
index 0000000..1ab9f6f
--- /dev/null
+++ b/lexical.h
@@ -0,0 +1,14 @@
+#ifndef LEXICAL_H_INCLUDED
+#define LEXICAL_H_INCLUDED
+
+#include
+using namespace std;
+
+string lexems(string testCmd);
+int cmdLexicalAnalysis(string cmd, std::vector &tokenStream, std::vector &tokens, int& pipeCount);
+int cmdSyntaxAnalysis(string cmd);
+int substrPos(string cmd, int it, int &strStartPos, int &strEndpos);
+int validateDir(string dir);
+int validateCmd(string cmd);
+
+#endif // LEXICAL_H_INCLUDED
\ No newline at end of file
diff --git a/lexical.h.gch b/lexical.h.gch
new file mode 100644
index 0000000..fd6d882
Binary files /dev/null and b/lexical.h.gch differ
diff --git a/lexical.o b/lexical.o
new file mode 100644
index 0000000..fe76e32
Binary files /dev/null and b/lexical.o differ
diff --git a/main.cpp b/main.cpp
old mode 100644
new mode 100755
index e69de29..e6351e2
--- a/main.cpp
+++ b/main.cpp
@@ -0,0 +1,163 @@
+/*input
+
+*/
+///-------------------------------------------------------------------------------------
+/*
+ AUTHOR: Akash Agarwal
+ 1405231007-Computer Science Department
+ IET LUCKNOW
+ LIFE MOTTO: while(!(suceed=try()))
+*/
+///--------------------------------------------------------------------------------------
+
+//Predefined #INCLUDES
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+//User Defined #INCLUDES
+
+#include "lexical.h"
+// #include "termcolor.hpp"
+using namespace std;
+/*
+ANSI colour codes.
+**Note that not all terminals support this; if colour sequences are not supported, garbage will show up.**
+
+Example:
+
+cout << "\033[1;31mbold red text\033[0m\n";
+Here, \033 is the ESC character, ASCII 27. It is followed by [, then zero or more numbers separated by ;,
+and finally the letter m. The numbers describe the colour and format to switch to from that point onwards.
+
+The codes for foreground and background colours are:
+____________________________________
+
+ foreground background
+
+black 30 40
+red 31 41
+green 32 42
+yellow 33 43
+blue 34 44
+magenta 35 45
+cyan 36 46
+white 37 47
+_____________________________________
+Additionally, we can use these:
+_________________________________________________________________
+
+reset 0 (everything back to normal)
+bold/bright 1 (often a brighter shade of the same colour)
+underline 4
+inverse 7 (swap foreground and background colours)
+bold/bright off 21
+underline off 24
+inverse off 27
+__________________________________________________________________
+
+See the table on Wikipedia for other, less widely supported codes.
+*/
+#define ANSI_COLOR_RED "\x1B[1;31m"
+#define ANSI_COLOR_YELLOW "\x1B[1;33m"
+#define ANSI_COLOR_BLUE "\x1B[1;34m"
+#define ANSI_COLOR_RESET "\x1B[1;0m"
+#define ANSI_COLOR_WHITE "\x1B[37m"
+#define ANSI_COLOR_GREEN "\x1B[1;32m"
+
+int main()
+{
+ string pathtoHome, username, hostname;
+ username = string(getenv("USER")); // If compiler is showing error: "basic_string::_M_construct null not valid"
+ // that means Ubuntu isn't exporting the variable like it should,
+ // put "export HOSTNAME" in "/etc/bash.bashrc" and the code works.
+ hostname = string(getenv("HOSTNAME")); // it will export both the username and the hostname.
+ pathtoHome = "/home/" + username;
+ chdir (pathtoHome.c_str());
+ static char* line_read = (char *) NULL;
+ while(true)
+ {
+ string prompt = "\n"
+ +
+ username
+ // +
+ // ANSI_COLOR_RED
+ +
+ "@"
+ // +
+ // ANSI_COLOR_GREEN
+ +
+ hostname
+ // +
+ // ANSI_COLOR_YELLOW
+ +
+ ":"
+ // +
+ // ANSI_COLOR_BLUE
+ +
+ boost::algorithm::replace_all_copy(boost::filesystem::current_path().string(), pathtoHome, "~")
+ // +
+ // ANSI_COLOR_RESET
+ +
+ "!>> ";
+
+
+ line_read = readline (prompt.c_str());
+
+ if (! line_read || strcmp(line_read,"exit") == 0)
+ {
+ cout << endl;
+ break;
+ }
+
+ /* If the line has any text in it, save it on the history. */
+ if (line_read && *line_read)
+ add_history (line_read);
+ try
+ {
+ string cmd(line_read);
+ cmdSyntaxAnalysis(cmd);
+ }
+ catch (const std::exception& e)
+ {
+ cout << e.what() << "\n";
+ }
+ }
+ return 0;
+}
+
+
+// /* A static variable for holding the line. */
+// static char *line_read = (char *)NULL;
+
+// /* Read a string, and return a pointer to it. Returns NULL on EOF. */
+// char *
+// rl_gets ()
+// {
+// /* If the buffer has already been allocated, return the memory
+// to the free pool. */
+// if (line_read)
+// {
+// free (line_read);
+// line_read = (char *)NULL;
+// }
+
+// /* Get a line from the user. */
+// line_read = readline ("");
+
+// /* If the line has any text in it, save it on the history. */
+// if (line_read && *line_read)
+// add_history (line_read);
+
+// return (line_read);
+// }
\ No newline at end of file
diff --git a/main.o b/main.o
new file mode 100644
index 0000000..bd587e8
Binary files /dev/null and b/main.o differ
diff --git a/parser.cpp b/parser.cpp
new file mode 100644
index 0000000..a28eed2
--- /dev/null
+++ b/parser.cpp
@@ -0,0 +1,51 @@
+#include
+#include
+#include
+#include